The Equivalence Mode Page lets you configure how Folder Diff Windows compares files.
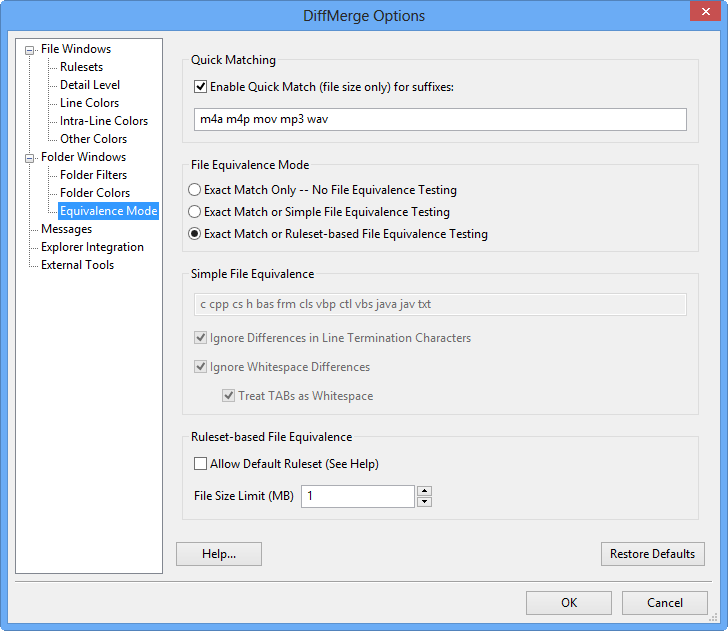
When a Folder Diff Window scans the file system, it compares each pair of files using one of these 2 techniques:
-
Quick Match Mode: When Quick Match is enabled and the file suffix is in the associated list, DiffMerge will just compare the sizes of the 2 files and report "qm" or "different". This is intended to help speed up scans when there are large media files in the folders. This method does not require either file to be read, so the results are an approximation.
-
Normal Mode: The contents of both files are read and compared. Pairs that are byte-for-byte identical are marked equal. Non-equal pairs are marked different.
When a difference is detected, DiffMerge can optionally rescan non-equal file pairs and ignore things like changes in line termination, changes in whitespace, and etc. in order to avoid reporting trivial differences. Files which only have ignorable differences as marked equivalent rather than different.
Please note that this second step is expensive and will cause DiffMerge to take longer to complete the scan. For this reason, there are 2 levels of equivalence testing, each with different levels of complexity:
Simple File Equivalence
Simple equivalence mode attempts to address the most trivial reasons for differences that are common to many types of text files:
-
It will only be applied to files with one of the listed suffixes.
-
During the rescan it will ignore differences in line termination characters and/or whitespace.
-
It operates as if the Detail Level is set to Lines Only mode.
-
It assumes that files are in an 8-bit encoding compatible with US-ASCII.
Simple equivalence mode DOES NOT look at upper/lower case, address character encoding issues, nor import the files into UNICODE.
Ruleset-based File Equivalence
Rulesest-based equivalence is a more thorough attempt to determine if the files only have trivial changes. It uses most of the settings in the corresponding Ruleset for each pair of files; this includes:
-
ignoring differences in character encoding by using the settings on the Character Encodings Page of the Ruleset Dialog and importing the files into UNICODE;
-
ignoring differences in line termination, whitespace, and letter case by using the settings on the Equivalence Mode Page of the Ruleset Dialog; and
-
stripping out lines matched by the Lines to Omit settings on the Ruleset.
Ruleset-based equivalence DOES NOT use the settings on the Line Handling Page of the Ruleset Dialog.
Ruleset-based equivalence operates as if the Detail Level is set to Lines Only and therefore does not use any of the Content Handling “Context” settings.
For Ruleset equivalence to work, Rulesets and automatic suffix matching must be enabled. For an individual Ruleset, character encoding selection must be automatic. If a Ruleset or character encoding cannot be automatically chosen, equivalence testing will either be skipped or the Default Ruleset chosen instead.
NOTE: Do not enable the Default Ruleset if you have binary files in your folders since the attempt to import the files into UNICODE will generally fail and just waste time.
As a performance consideration, you may want to set an upper file size limit for Ruleset equivalence testing. No ruleset-based equivalence testing will be done on files that exceed this limit.